在 OpenShift 4.20 上建置模型服務:vLLM + Qwen 3 8B + Open WebUI
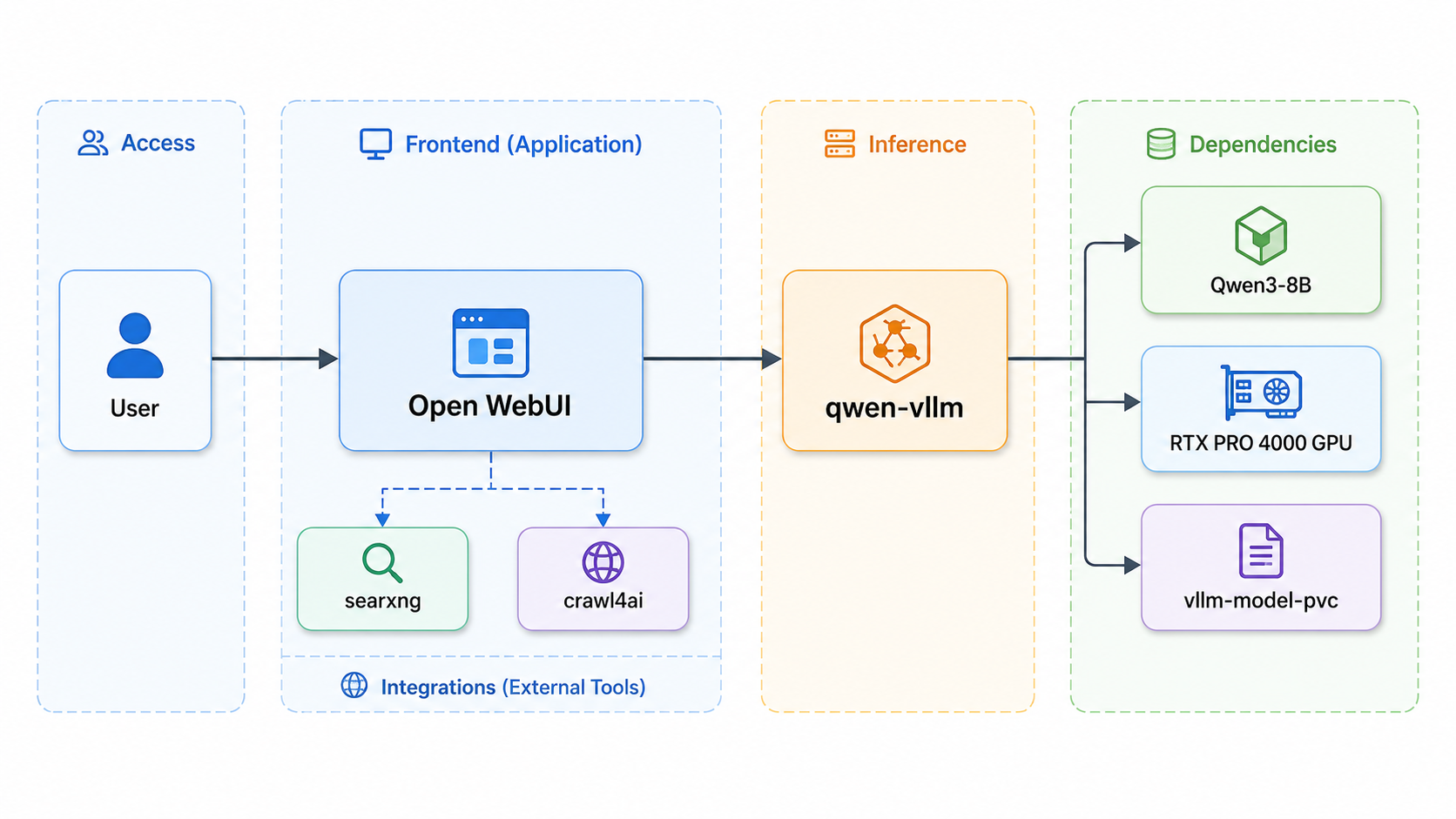
去年我在 2025 iTHome 鐵人賽 - 30 天帶你實戰 LLMOps:從 RAG 到觀測與部署 的 Day17 - LLM 部署策略選型:雲端 vs 本地 vs 混合架構(成本與隱私) 有介紹過雲地部署 AI 模型大略的成本概念。所以我也想實際在我的地端環境裡面簡單的建置看看大語言模型服務,走過一遍實際的建置流程,才會有深刻的印象。
適用環境:RHEL 9 / OpenShift 4.20 / RTX PRO 4000 Blackwell GPU
我的環境建置成本和選型可以參考這篇:Homelab 神桌 2.0 建置紀錄。
規劃
如封面圖所示,我們必須建置給使用者輸入對話的 Open WebUI 入口、輔以 searxng 和 crawl4ai 作為網路查詢資料用途、後端使用 vLLM 作為模型的部署工具,讓模型可以作為大腦提供思考能力。假設環境裡有多個 vLLM 的 deployments 部署, Open Web UI 可以提供使用者自由選擇不同的模型,當然也可以串接 AI Agent 和 MCP。
為何選擇 Open WebUI?
因為建置的時候我是比較常用 ChatGPT, 而且這個 Portal 專案可以模擬多人使用情境新增不同使用者、控制使用者權限、限制哪些模型可以開放,算是模擬企業情境很好用的專案。

可能你也會有疑問,為什麼不是選擇最常聽到的 Ollama ,而是選擇 vLLM 作為部署的選擇?
以我的環境來說,我不只想在自己電腦上跑模型,還要在 OpenShift 裡面把模型變成一個可被 Open WebUI 呼叫、監控、調度的服務,重點是必須要模擬多人使用者、多併發需求的 Production 場景。本文聚焦在 OpenShift 上部署可觀測、可調校的 LLM inference service,因此選擇 vLLM作為推論引擎。若你的需求是快速在OpenShift上跑起一個LLM + Open WebUI,Ollama 也是可行的選擇。
以下是簡易比較表:
| Ollama | vLLM | |
|---|---|---|
| 核心定位 | 易用的本地 / 私有 LLM runtime | 高吞吐、記憶體效率佳的 LLM inference serving engine |
| Kubernetes / OpenShift | 可透過 Ollama Operator 部署與管理,已有 Kubernetes / OpenShift 實作與教學 | 天生更常被用在模型服務化、高併發推論、MLOps / AI platform 場景 |
| 使用體驗 | 上手簡單,適合快速拉模型、測模型、接 Open WebUI | 需要理解 serving 參數、GPU 記憶體、KV cache、batching、模型格式 |
| 模型格式 | 主要使用 Ollama model / GGUF 生態,也可透過Modelfile 匯入模型 |
主要使用 Hugging Face model repo,預設優先載入 safetensors,沒有才 fallback 到 PyTorch bin |
| 模型相容性 | Ollama 模型與 vLLM 模型不能直接互通;若是自訂或微調模型,常需要轉換或建立Modelfile |
只要是 vLLM 原生支援、Transformers-compatible,或能透過 custom model/remote code 載入,就比較直接 |
| 自訂模型 | 可以做,但通常要處理 GGUF / Modelfile / adapter 匯入流程 | 對 Hugging Face / Transformers 格式的自訂模型比較自然 |
| 效能導向 | 易用、離線、本地體驗優先 | Throughput、continuous batching、PagedAttention、GPU utilization 優先 |
| 適合場景 | 個人開發、內部小型服務、PoC、local-first LLM、快速 Demo | 多人共用、高流量 API、平台化部署、正式 inference endpoint |
一:vLLM 推論引擎部署
這邊會需要調查一下 GPU 適合使用的模型。因為我的 GPU 只有少少的 24 GB vRAM,如果選擇過大的模型(比方說 DeepSeek-R1-Distill-Qwen-32B)模型可能根本載不起來;就算勉強載起來,也會因為 KV cache 空間不足,導致 context 長度、並發能力、表現的穩定性都大幅下降。
比方說以 32B 模型來說,如果用 BF16 / FP16,光模型權重大約就是:
1 | 32B parameters × 2 bytes ≈ 64GB |
這邊還沒有算上 CUDA / PyTorch runtime overhead、vLLM engine overhead、activation / temporary buffer、KV cache、CUDA graph / compile cache、fragmentation 等 vRAM 開銷,直接啟動可能就會遇到 CUDA out of memory 的錯誤。就算勉強選用達到 vRAM 上限的模型,也會因為 KV cache 不足導致吞吐量較低、模型上下文變短、更甚者會跑到一半就 OOM。不過跑不起來不是模型的問題,\\x7e\x7e是我錢包的問題\x7e~。
Deployment 核心配置(qwen-vllm-deployment.yaml)
1 | apiVersion: apps/v1 |
部署指令
1 | # 部署 vLLM (第一次 pulling 會花很久的時間) |
pod 跑起來,成功進入 vLLM engine 初始化階段 log 如下:
1 | 這代表 vLLM 找得到 GPU,也認得 Qwen3-8B。 |
從映像檔下載到跑起來所花費的時間
| 階段 | 第一次啟動可能時間 |
|---|---|
| Pull vllm-openai image | 5–15 分鐘,慢的話更久 |
| 下載 Qwen/Qwen3-8B 模型 | 10–40 分鐘,看網路 |
| 載入模型到 GPU | 1–5 分鐘 |
| 建 KV cache / CUDA graph | 1–5 分鐘 |
| 總時間 | 大概 15–60 分鐘 |
vLLM Log 解讀
以下以實際運行約 5 分鐘(17:35–17:40)的日誌為例,說明各項指標的意義與觀察結果。從這段日誌可以看到屬於輕負載情境,GPU 仍有大量餘裕。若要測試系統上限,可嘗試提高並行請求數量。
1 | (APIServer pid=1) INFO 06-04 17:39:54 [loggers.py:271] Engine 000: Avg prompt throughput: 16.3 tokens/s, Avg generation throughput: 38.0 tokens/s, Running: 1 reqs, Waiting: 0 reqs, GPU KV cache usage: 3.7%, Prefix cache hit rate: 26.4% |
吞吐量
Generation throughput 全程穩定維持在約 37–38 tokens/s,反映 GPU 生成速度固定。Prompt throughput 變動較大(0–338 tokens/s),主要受 prefix cache 命中率影響:命中時不需重新計算,速度會明顯提升。出現並行請求時,generation throughput 可提升至 60 tokens/s。
GPU KV Cache
使用率大多維持在 1–8%,最高僅 16.2%(發生於並行請求時),每次請求結束後自動歸零。
Prefix Cache Hit Rate
| 時間 | Hit Rate |
|---|---|
| 17:35–17:36 | 0.0%(冷啟動) |
| 17:37:14 | 1.1% |
| 17:38:14 | 16.8% |
| 17:39:34 | 36.5%(最高) |
| 17:40:34 | 27.7% |
Hit rate 隨請求累積逐漸上升,代表重複的 prompt prefix(例如固定的 system prompt)持續被 cache 命中,有效降低後續請求的計算成本。
二:網路連線與服務發現
建立 ClusterIP Service
1 | oc apply -f - <<EOF |
連通性驗證
1 | # 確認 Endpoints 已掛載(應顯示 Pod IP) |
三:Open WebUI 前端部署
注入環境變數
1 | oc set env deployment/open-webui \ |
取得外部存取網址,加上網路搜尋引擎以及爬蟲
1 | oc get route chat-ai -n llm-inference |
之後就可以開始對話、並進行測試。我這邊有放上搜尋引擎和爬蟲程式協助我連到外網抓取股價或是天氣等常見資訊:
- crawl4ai — 網頁爬蟲與內容擷取工具,專為 AI 應用設計。可以把網頁內容轉成乾淨的 markdown 或結構化資料,方便直接餵給 LLM 使用。常見用途是 RAG pipeline 的資料來源、網頁內容摘要、或讓 AI agent 瀏覽網頁。
- searxng — 開源的自架搜尋引擎,可以聚合 Google、Bing、DuckDuckGo 等多個搜尋引擎的結果,但不追蹤使用者。在 AI 場景裡常被用來給 LLM 提供即時網路搜尋能力,是 Open WebUI 等工具的常見搭配。
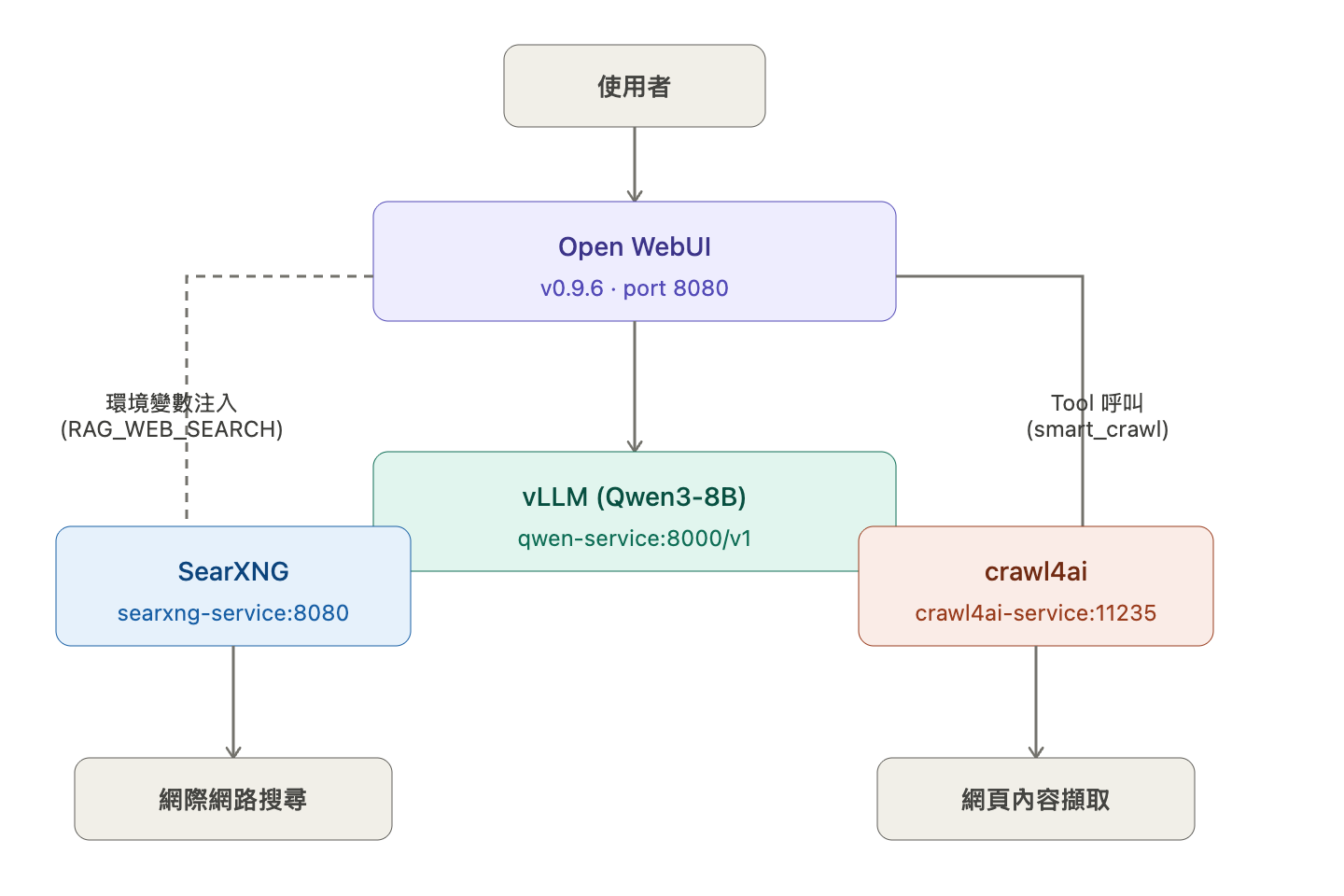
crawl4ai
我在同個 namespace 下面部署了 crawl4ai Deployment。這是跑在 cluster 裡的爬蟲服務,提供 REST API 給 Open WebUI 裡面的 LLM 呼叫 crawl4ai API 的 Tool 使用。以下是該 Tool 的程式碼:
1 | import requests |
Searxng
Searxng 直接起一個 Deployment 和 Service,並且 Open WebUI 用環境的變數指到內部 Service URL,就可以在 Open WebUI 裡面直接開啟搜尋功能。
1 | - name: ENABLE_RAG_WEB_SEARCH |
四:GPU 效能監控與壓力測試
即時監控指令
1 | # 持續監控顯存、功耗、溫度(Blackwell): 每五秒顯示一次 |
實測數據
這邊用之前測試的 Qwen 2.5 7B @ 32K Context 作為範例,因為我測試過不同的模型其實在 GPU 上面的指標表現都差不多,都會超過八十度C、也幾乎都會吃滿算力,這邊就是實測時的欄位說明。
1 | +-----------------------------------------------------------------------------------------+ |
數據解讀:
- 顯存(VRAM): 22,270 MiB / 24,467 MiB,使用率約 91%,符合
--gpu-memory-utilization 0.90設定,剩餘 buffer 供 KV Cache 動態分配。 - 功耗: 144W / 145W,幾乎頂到 TDP 上限,說明 Blackwell 在 AWQ 量化推論下仍能充分榨取算力,並非功耗受限瓶頸。
- 溫度: 81°C,風扇轉速 53%。RTX PRO 系列 Tj Max 為 90°C,仍有約 9°C 熱餘量,散熱表現健康。
- GPU 使用率: 100%,推論期間 GPU 無閒置,為純運算瓶頸(compute-bound),而非 I/O 或記憶體頻寬瓶頸。
- 執行程序:
VLLM::EngineCore(PID 84303),確認 vLLM 獨佔 GPU,無其他進程搶占資源。 - CUDA 版本: 13.0,驅動版本 580.105.08,為支援 Blackwell 架構的最新驅動分支。
五:使用者管理與權限
已解決問題: 新註冊使用者無法看到模型。
- 啟用帳號:
Admin Panel→Users→ 將狀態從Pending改為Active - 公開模型:
Workspace→Models→ 確認 Qwen 模型可見性設為Global
結果展示
如圖所示,除了文字對話之外,也可以產出基本的流程圖。就地端迷你模型(8B)而言,算是非常強的表現了:
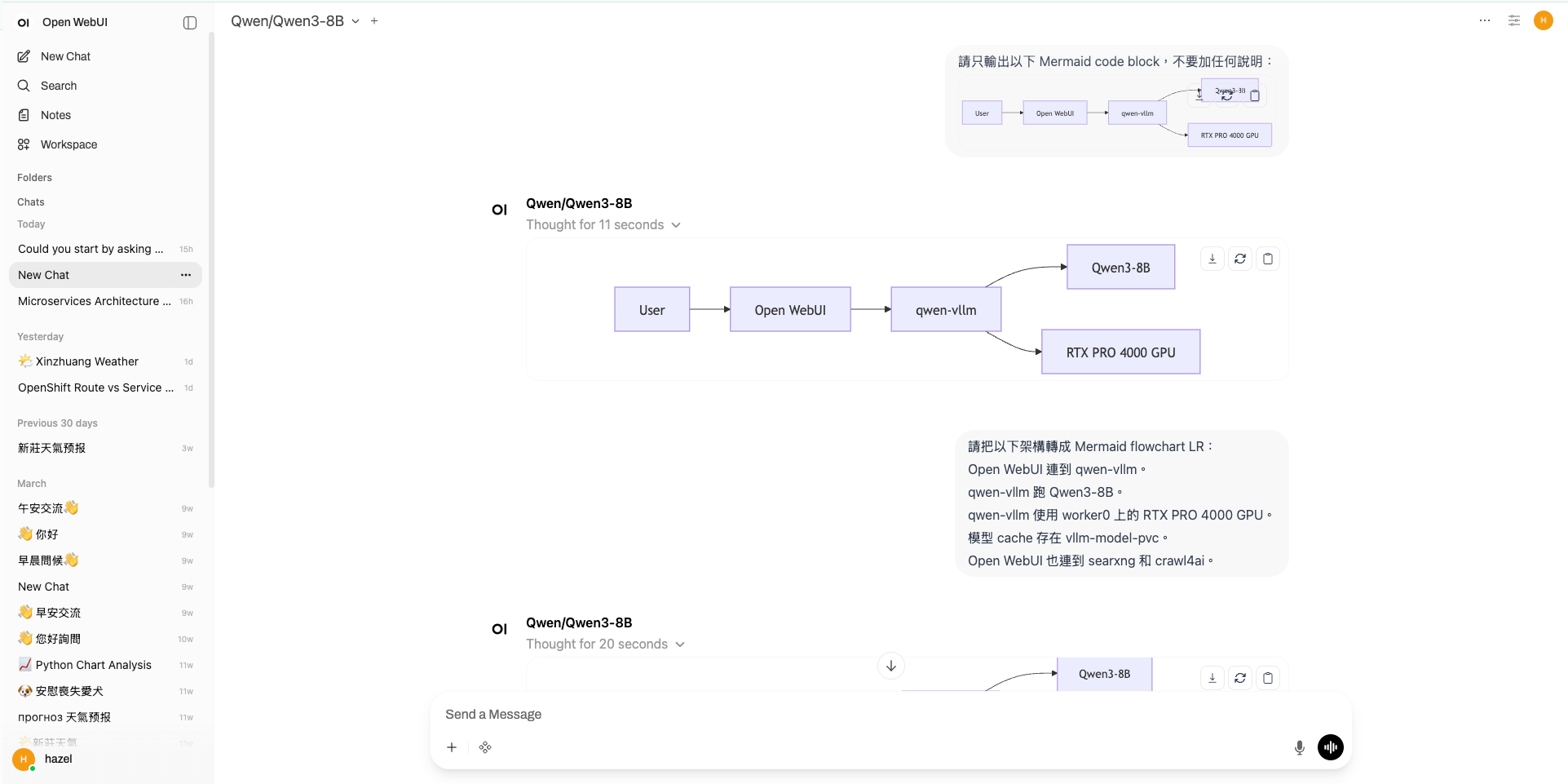
我有試過 Qwen2.5-7B,但對話測試結果實在太落漆。雖然我沒有深入研究模型之間的差異性,但就體感上來說換成 Qwen3-8B 結果好超多!我稍微查了一下原因:
Qwen3-8B 有 thinking mode,Qwen2.5-7B 沒有。 Qwen3 在同一個模型裡支援 thinking / non-thinking 切換,對於技術問題、架構分析、YAML 除錯這類需要多步推理的任務,thinking mode 的回答品質明顯更好,而 vRAM 壓力我自己實測兩個模型是差不多的。
Reference
Ollama vs vLLM 比較 / 效能
- Ollama or vLLM? How to choose the right LLM serving tool for your use case — Red Hat Developer
- Ollama vs. vLLM: A deep dive into performance benchmarking — Red Hat Developer
- vLLM vs Ollama: Key differences, performance, and how to run them — Northflank
- Ollama vs vLLM: Performance Benchmark 2026 — SitePoint
Kubernetes / OpenShift 部署
- Deploying Ollama on OpenShift with the Ollama Operator — Medium
- Running LLMs on Kubernetes — bespinian
模型格式差異
- Ollama vs vLLM: Local vs Production LLM Inference Compared — Spheron(有說明 GGUF vs safetensors 的差異)
crawl4ai
- GitHub - unclecode/crawl4ai — 官方 repo,有完整說明與 API 文件
- crawl4ai 官方文件 — 包含 Docker 部署、API 使用方式
SearXNG
- GitHub - searxng/searxng — 官方 repo
- SearXNG 官方文件 — 包含設定、搜尋引擎清單、API 說明
SearXNG 整合
- Open WebUI × SearXNG 設定文件 — 包含環境變數設定方式,跟你的 YAML 完全對應
- Open WebUI Web Search 總覽
Tools 整合
- Open WebUI Tools 文件 — 說明 Workspace Tools(對應你的 crawl4ai
smart_crawl)的運作方式