[OpenShift 監控系列 - 3] Custom Query on OpenShfit Developer Dashboard
承襲上篇系列文 -
前兩篇主要是以 PaaS 的角度談收集 Metrics 的方法,本篇會細分到開發面,使用一個實例去示範如何透過 OpenShift 的 Dashboard 查看 Metrics(指標)。
環境:
🌿 OpenShift 4.7
🌿 Prometheus Operator: 0.44.1
🌿 Thanos: 0.17.2.
🌿 Postman v8.2.1
🌿 Grok Exporter 1.0.0.RC5
🌼 什麼是 Custom Query ?
此篇文會出現是因為我在 Developer Dashboard 下的 Custom Query。
這個功能適合一個場景:假若我今天是一個開發者,而我只是想要在 OpenShift 部署 AP 觀察我程式的 API 呼叫次數、HTTP responses 次數(比方說 response 是 200 的次數),不想管那啥 Prometheus Server 建置問題的話,就可以使用這個功能!
如下示意圖所示,可以看到 Custom Query 是以 Projects 為單位(對應到 Kubernetes 的 namespace)。
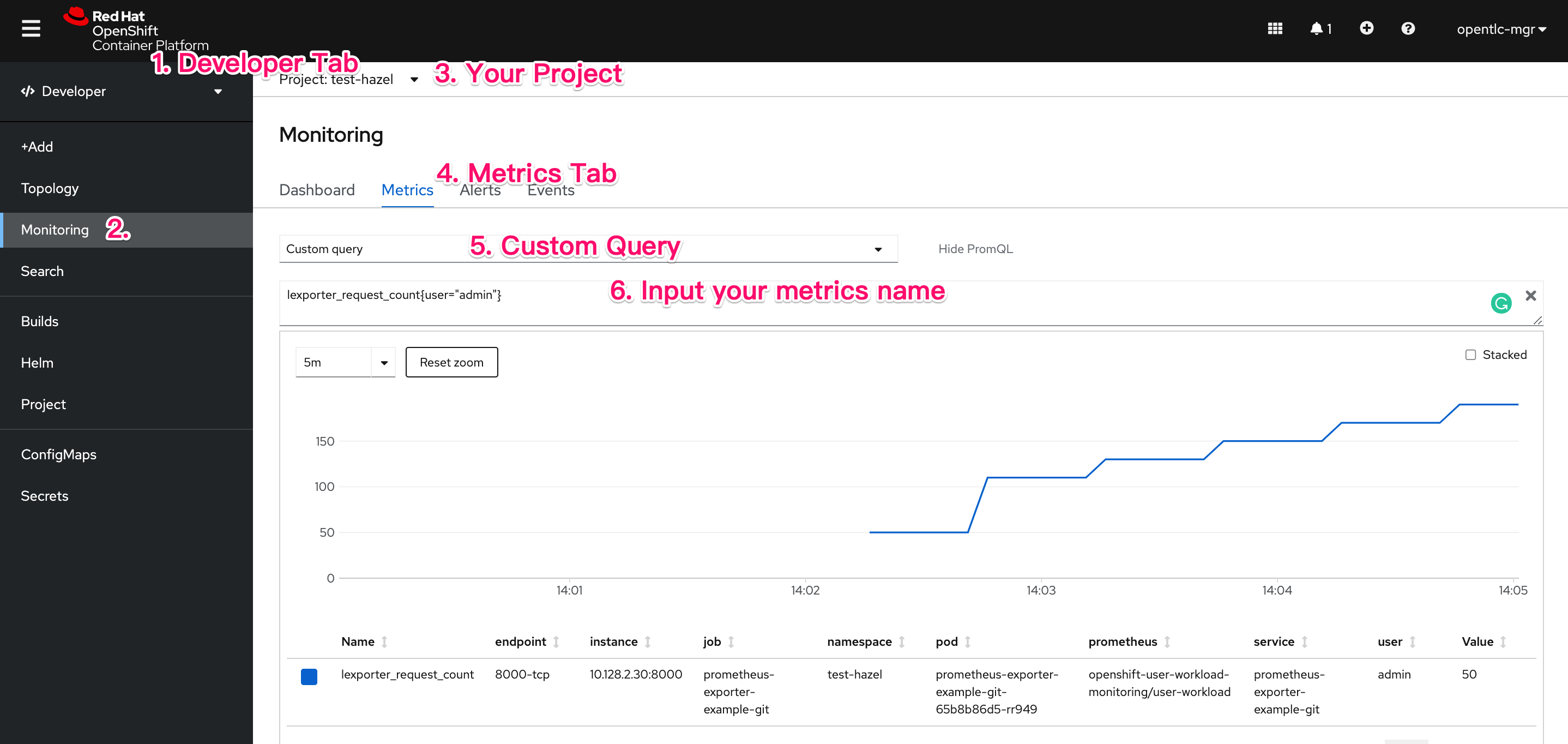
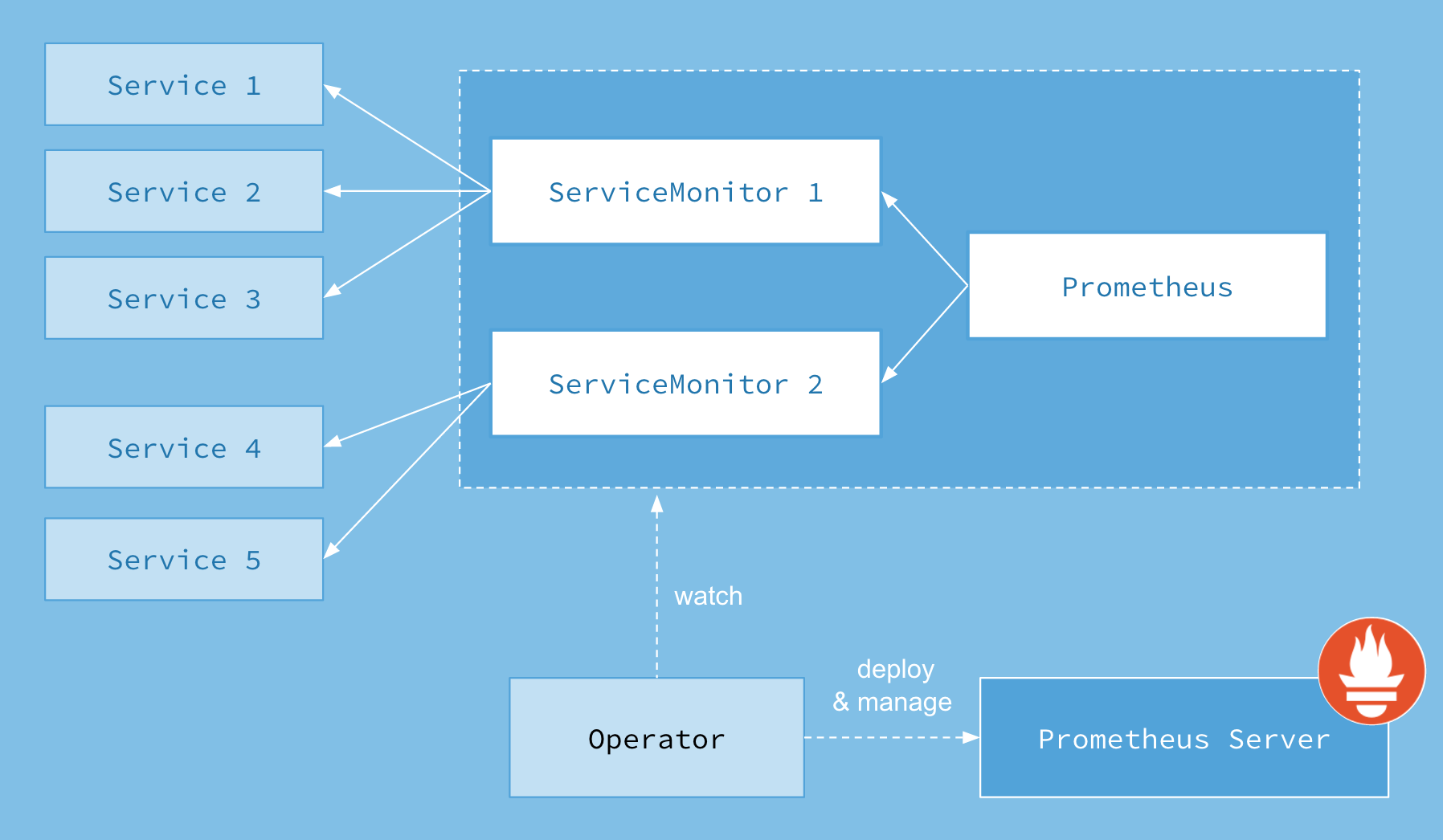
雖然說我們可以 Don’t give 建置 a shit,但還是要知道該怎麼設定,在 Kubernetes 或 OpenShift 這樣的容器平台上,通常會使用 Operator 進行建置,OpenShift 本身的 Prometheus 亦如是,Prometheus 這個專案自己也有 Operator,讓 Operator 去煩惱 Prometheus 從建置到死而復生的生命週期。
Prometheus 的設計就是讓 Service Monitor 去監控 Kuberbetes Service 的 port,使用這個 port 回傳的 metrics 就會被收在 Prometheus Server 。
🌼 在 OpenShift 上啟用權限
這個步驟也可以直接參考官方文件
首先請 OpenShift 管理者(亦即擁有 cluster-admin role 的帳號)apply 以下 ConfigMap,這個動作是讓 OpenShift 上的 Prometheus 可以監管非 OpenShift 本身的 project。
註:OpenShift 4.7 版如果要使用 Custom Query 的話必須把先前安裝(不管什麼形式)、 非 OpenShift 內建的 Custom Prometheus Instances 拿掉。
- OpenShift 4.6 (含)以上版本請用以下 ConfigMap
1 | apiVersion: v1 |
- OpenShift 4.5 (含)以下版本請用以下 ConfigMap
1 | apiVersion: v1 |
除了把這個 ConfigMap 部署在 openshift-monitoring 之外,也可以選擇另外一種方式:修改在 openshift-user-workload-monitoring 這個 project 底下的 user-workload-monitoring-config 這個 ConfigMap,兩者效果一樣。
接下來可以用指令檢查結果
1 | oc -n openshift-user-workload-monitoring get pod |
建立 role binding,讓該使用者可以使用 OpenShift monitoring 監控自己的 Project,需要加入 monitoring-rules-view、monitoring-rules-edit 以及 monitoring-edit 這三個權限。
1 | # oc policy add-role-to-user <role> <user> -n <namespace> |
另外再針對該名使用者加入可以在 openshift-user-workload-monitoring 修改 monitoring config 的權限。
1 | # oc -n openshift-user-workload-monitoring adm policy add-role-to-user user-workload-monitoring-config-edit <user> --role-namespace openshift-user-workload-monitoring |
🌼 在 OpenShift 上部署範例程式碼並且觀察結果
首先部署 Red Hat 官方網站範例程式碼
1 | cat > prometheus-example-app.yaml |
部署完後可以透過 Developer Tab 或者是指令看到以下畫面
1 | oc get routes -n ns1 |

可以看到這支 AP 收集了兩條 metrics,待會在 Dashboard 上我們會用到
1 | http_requests_total{code="200",method="get"} |
接下來部署 ServiceMonitor,讓 OpenShift 自帶的 promentheus server 能夠收集 metrics
1 | cat > example-app-service-monitor.yaml |
部署完後回到 Developer Dashboard > Monitoring > Metrics > 下拉式選單選 Custom Query
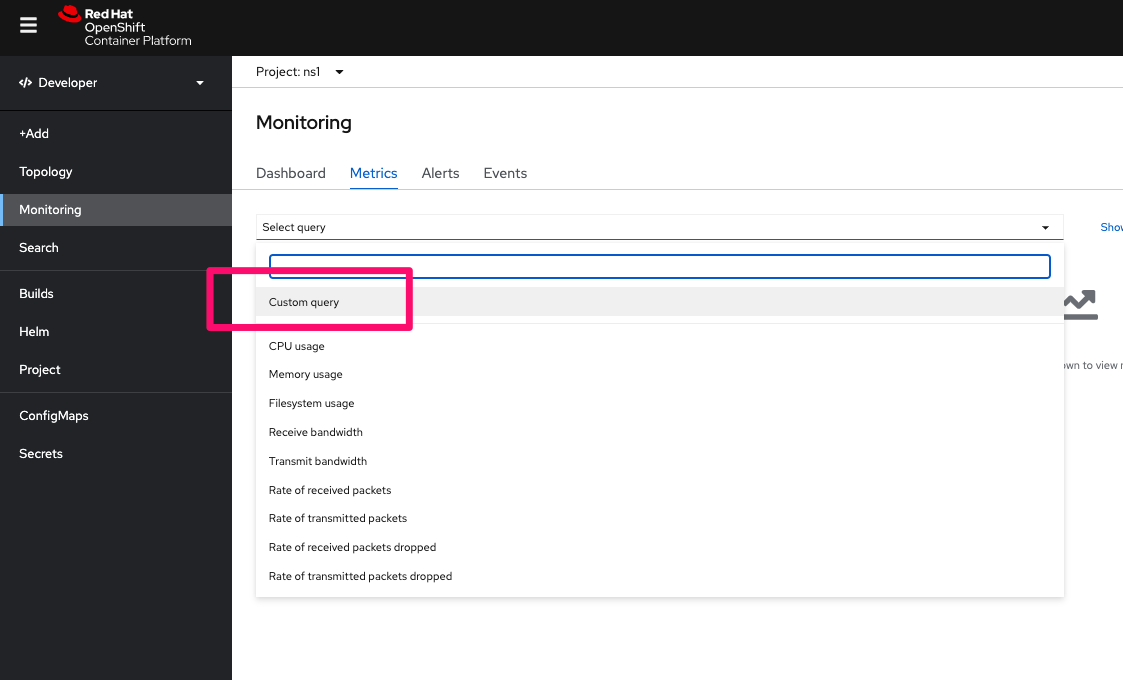
輸入剛剛看到那兩條 metrics 其中之一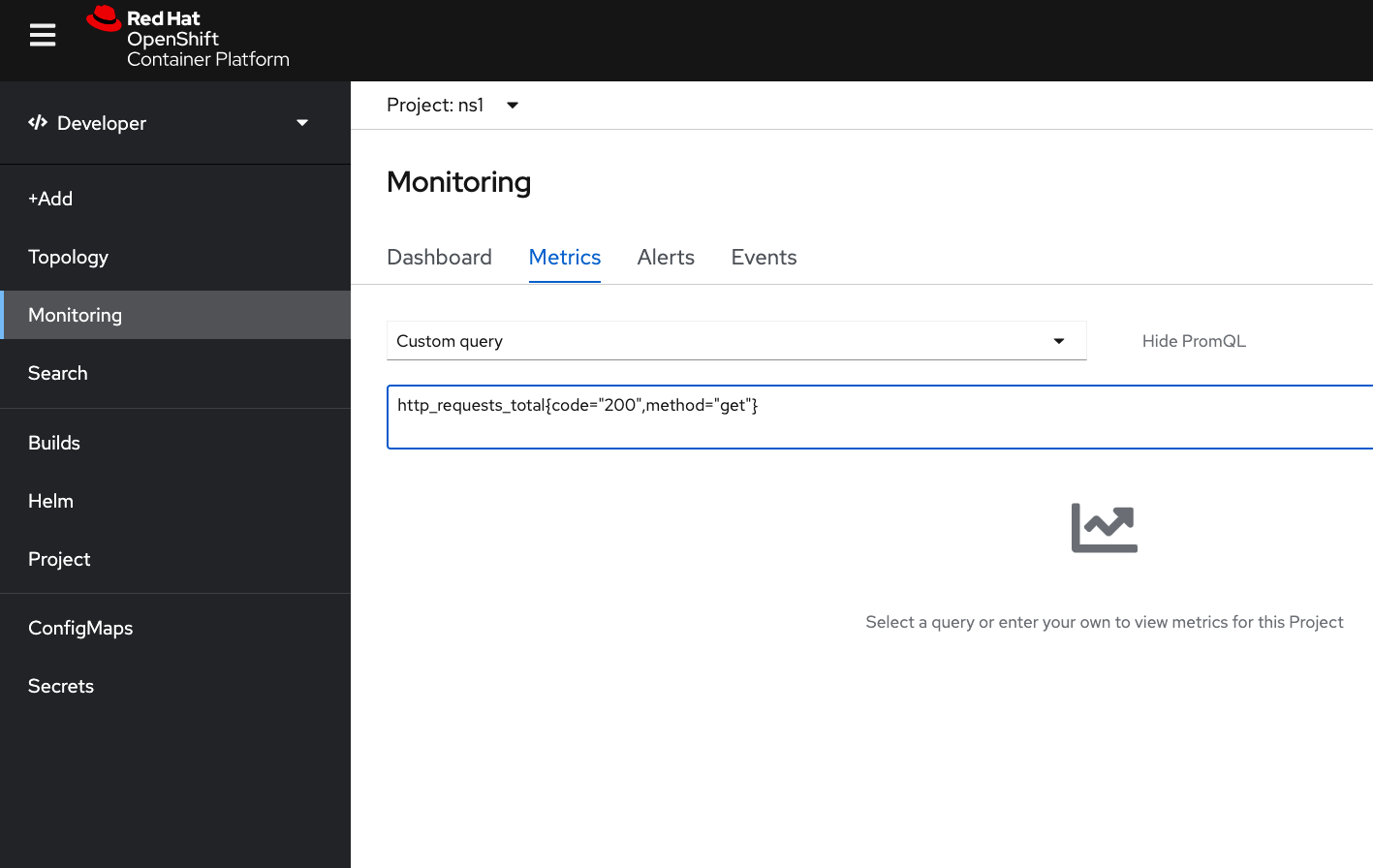
看到 metrics 了!在這邊可以看到有 Service Name、Pod Name等資訊。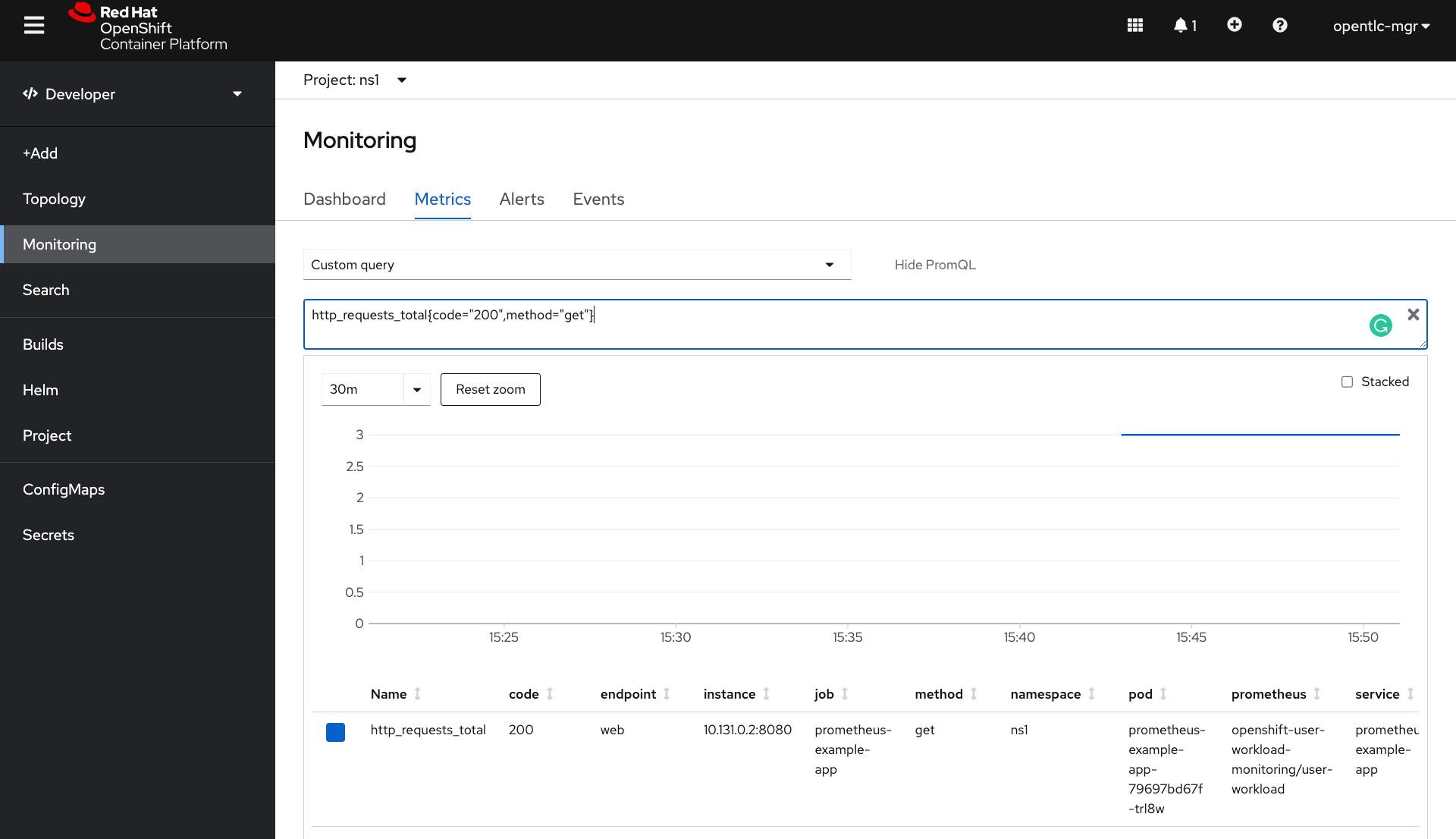
🌼 應用情境
如果需要類似 API Manager 常常附帶的監控功能或是覺得另外買監控軟體太貴,可以使用 Custom Query 的功能,還可以針對想要看的數值寫 metrics 來收就好,彈性程度比較高。
有需要的人可以參照 Prometheus 官方文件 來學習 Metrics 的寫法,如果覺得 Prometheus Dashboard 呈現太陽春,甚至可以拉 Grafana Dashboard 做成如下圖漂亮的圖表。
🐥 Reference
🌟 Monitoring Quarkus apps using Micrometer and Prometheus into OpenShift
🌟 Monitoring your own workloads in the Developer Console in OpenShift Container Platform 4.6
🌟 Prometheus Operator
🌟 Enabling monitoring for user-defined projects on OpenShift 4.7
🌟 Manage Metrics on OpenShift with example codes
🌟 Prometheus Metrics Type